Pallas 设计#
本文档解释了 Pallas 的初始设计。这是早期做出的一些设计决策的快照,自那时以来 Pallas 的特定 API 可能已更改。
简介#
JAX 被广泛应用于各种工作负载,从大规模机器学习到科学计算。JAX 的成功故事在很大程度上也是 XLA 的成功故事,XLA 是 JAX 主要的目标编译器 —— XLA 为加速器编译 JAX 程序,并使 JAX 能够扩展到最大的 ML 模型。JAX 在 XLA 的表示形式 HLO 中描述逻辑计算。HLO 描述了计算在逻辑上如何发生,而不是物理上如何发生。给定一个逻辑的 HLO 计算,XLA 决定如何物理地执行该计算。对于各种 ML 应用,XLA 在编译用户程序方面做得很好,但不可避免地,一些用户会遇到 XLA 的局限性。在这种情况下,我们需要提供一个“逃生舱口”,允许专家编写手工调优的内核,从而在当时胜过 XLA。此外,ML 系统研究的进展需要一些时间才能纳入 XLA,而用户通常希望提前运行这些进展。随着时间的推移,编译器可以整合通过手工调优的内核在实验中验证的优化。
XLA 确实提供了 CustomCall 机制作为逃生舱口,但这要求用户编写 C++,并且在 GPU 上需要用户学习 CUDA 编程模型。CUDA 编程模型对于许多机器学习 GPU 内核(如矩阵乘法)来说,可以说过于底层,即使是专家用户也很难使用 CUDA 来实现高效的矩阵乘法或多头注意力。不仅如此,JAX 用户通常熟悉 Python 和 NumPy 风格的数组编程,这不涉及编写任何 C++ 或考虑 GPU 并行性。所有流行的机器学习框架都秉承这一理念:使用诸如 matmul 或 convolution 等高级操作来处理(通常是)数组。不幸的是,这意味着通过 CustomCall 实现自定义操作是一项很大的投入,可能需要学习 C++ 和/或 GPU 编程。
Triton 是由 OpenAI 构建和维护的 GPU 编译器,它在 ML 编译器领域掀起了一场风暴。Triton 提供了两全其美的方案:一种用于 GPU 内核的基于数组的编程模型。Triton 是 PyTorch 2.0 中 torch.compile 的主要代码生成途径,通过 Torch Inductor 库实现。Triton 为了提供更易于访问的编程模型而积极隐藏了 GPU 编程的一些方面,该模型可以从 Python 中使用,并从更高级的表示中生成优化的代码。虽然 GPU 比 Triton 提供的功能更灵活,但在 ML 领域,Triton 对于许多应用来说似乎足够具有表达力。
在本文档中,我们描述了 Pallas,它是 JAX 的一个扩展,可以使用类似 Triton 的模型为 GPU 和 TPU 启用内核编程。基于 JAX 的内核语言具有以下几个优势:
虽然 Triton 向用户公开了类似 TPU 的编程模型,即为 L1 缓存中的数组切片编写程序,但它针对 GPU 进行了专门设计,我们无法直接为 TPU 编译 Triton。例如,Triton 提供了专门用于处理并行写入的原子操作,这在 TPU 上不一定有意义。更高级的前端可以抽象化平台的细节,同时只展示基于切片的编程模型。因此,内核将在不同的硬件平台上可移植。
JAX 作为数值计算的基于跟踪的前端,既成熟又得到了广泛应用。通过将内核编程语言嵌入到 JAX 本身,我们可以重用 JAX 的跟踪基础设施,并提供一个用户已经熟悉的类似于 NumPy 的前端。
JAX 转换是其成功的关键,它允许用户表达简单的程序,但将其转换为实现复杂的功能。我们可以利用相同的转换(vmap、jvp 等)来转换用户编写的内核。
悬而未决的问题是:JAX 是否适合作为内核语言?我们认为是适合的。Triton 表明,数组编程语言对于编写 GPU 内核是可行的,而 JAX 正是如此。JAX 也被证明是编译器和程序转换的灵活前端。
我们按如下方式描述 Pallas:我们首先描述我们扩展 JAX 以支持编写自定义内核的方式。然后,我们展示如何将 Pallas 降级到 Triton 和 Mosaic。最后,我们描述通过 JAX 转换转换 Pallas 内核的现有和潜在方式。
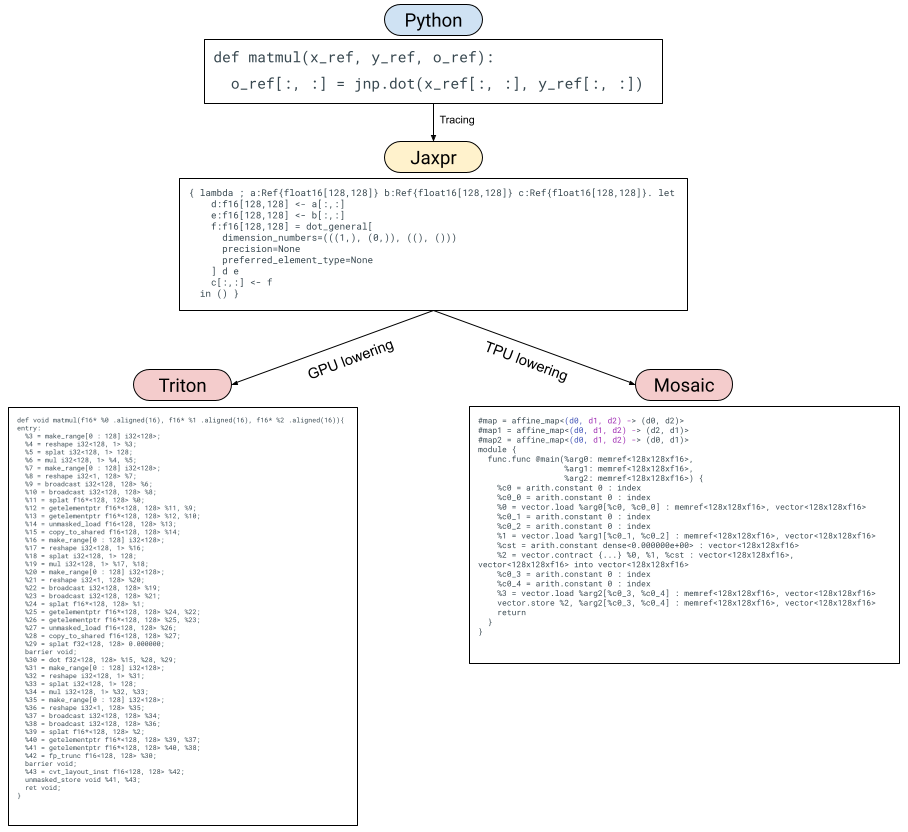 Pallas 降级路径的可视化
Pallas 降级路径的可视化
Pallas:为内核扩展 JAX#
我们想要强调的关键是,Pallas 只是 JAX,并进行了一些扩展
用户现在在他们的 JAX 代码中使用名为
Ref的引用类型。这使用户可以更精确地控制 JAX 中的内存访问和布局,使其更接近物理布局。用户使用 JAX 原语的子集以及一组 Pallas 特定的原语来编写他们的 JAX 程序。
用户通过一个特殊的
pallas_call高阶函数将他们的 Pallas 内核嵌入到一个外部 JAX 程序中,该函数在映射中执行内核。它类似于pmap或shard_map,只是使用了对共享内存的引用。
我们将逐一通过示例介绍这三个扩展。
请注意,这些 API 仍然是实验性的,可能会发生更改。
引用类型#
让我们看一个用于添加两个向量的 Pallas 程序示例
import jax
import jax.numpy as jnp
from jax.experimental import pallas as pl
def add_kernel(x_ref, y_ref, o_ref):
# In this code, `x_ref`, `y_ref` and `o_ref` are (8,)-shaped `Ref`s
x = x_ref[:]
y = y_ref[:]
o_ref[:] = x + y
x, y = jnp.arange(8), jnp.arange(8, 16)
add = pl.pallas_call(add_kernel, out_shape=jax.ShapeDtypeStruct((8,), jnp.int32))
add(x, y)
与常规 JAX 程序不同,add_kernel 不接收不可变的数组参数。相反,它被提供了可以使用类似 NumPy 的语法读取和就地更新的引用。Ref 不是 Pallas 特有的概念 —— 它们被引入 JAX 以表示有状态的计算。但是,我们可以在编写操作可变内存的内核时利用它们。
Pallas 内核不仅接收对应于内核输入的 Ref,还接收输出的 Ref(在 pallas_call 中通过 out_shape 指定)。Ref 是特殊的类型,在没有先读取的情况下,不能传递到通常的 JAX 原语集中。当你从 Ref 读取时,你会得到一个 JAX Array 类型,并且你必须将一个 Array 写入到一个 Ref 中。
从 Ref 读取/写入#
从 Ref 读取相当于将一个数组加载到内存层次结构的最低级别(GPU 上的 L1 缓存和 TPU 上的向量寄存器)。写入 Ref 是类似的。
def f(x_ref, o_ref):
# Using vanilla Python indexing
x = x_ref[0, 2:5, :]
# Or via Numpy advanced int indexing
o_ref[jnp.arange(3), :] = x
# Note that in order to use NumPy advanced int indexing, you need to broadcast the indices against each other into the desired multidimensional shape:
def f(x_ref):
# Assume x_ref is (8, 4) and we want to read out a (2, 3) slice
x = x_ref[jnp.arange(2)[..., None], jnp.arange(3)[None, ...]]
可以使用类似的 __setitem__ 样式索引完成对 Ref 的写入。
其他形式的索引(例如,动态切片)可以通过 pallas.load 和 pallas.store 完成,这是新的 JAX 原语,旨在使从内存加载和存储到内存更容易。我们将在稍后讨论这些新原语。
使用新的 Pallas 原语扩展 JAX#
由于 JAX 在设计时考虑了 HLO,因此 JAX 原语集与 HLO 操作集非常相似。以新的编译器(例如 Triton 或 Mosaic)为目标意味着我们可能需要使用新的特定于新编译器的原语来补充 JAX 的原语。同时,我们可能无法降低所有 JAX 原语,因此我们需要将其限制为子集。
由于 Pallas 最初是在考虑 Triton 的情况下设计的,因此我们提供了一组针对 Triton 编程模型的新原语。正如我们稍后将展示的那样,我们也可以将这些原语降级到 Mosaic。
pallas.load 和 pallas.store#
pallas.load 和 pallas.store 是允许从内存加载和存储到内存的原语。与 __getitem__ 和 __setitem__ 不同,它们更灵活,但代价是更加冗长。具体来说,你可以使用 pallas.dynamic_slice (简称 pallas.ds)构造(也许应该将其上游到 JAX 中以与 Ref __getitem__ 和 __setitem__ 一起使用)。
def f(x_ref, o_ref):
# Reading from memory via pallas.load
x = pl.load(x_ref, (0, slice(2, 5), slice(None)))
# Using integer indexing automatically broadcasts
x = pl.load(x_ref, (0, 2 + jnp.arange(3), slice(None)))
# You can also use `pl.dynamic_slice` (`pl.ds` for short) objects as well
pl.store(o_ref, (0, pl.ds(start=2, size=3), slice(None)), x)
pallas.load 和 pallas.store 还支持通过 mask 参数进行掩码。
def f(x_ref, o_ref):
# Reading from memory via pallas.load
idx = jnp.arange(8)
mask = idx < 5
x = pl.load(x_ref, (idx,), mask=mask, other=float('-inf'))
在进行越界加载/存储时,掩码很重要。掩码的操作语义可以由编译器决定(如果我们正确理解文档,则 Triton 会避免从内存读取/写入,如果它被掩码了)。
pallas.program_id 和 pallas.num_programs#
正如我们即将看到的那样,我们将多次执行相同的 Pallas 内核(并行或在管道中,具体取决于后端)。这些新原语告诉我们内核执行的“位置”。
pallas.program_id 接收一个轴参数,该参数告诉我们此内核当前正在多维网格的哪个轴中的哪个索引中执行(类似于 CUDA 编程中的 threadId 或 jax.pmap 中的 lax.axis_index)。请注意,我们目前正在借用 Triton 的“程序”术语,将来我们可能希望将其更改为 JAX 用户更熟悉的术语。
def f(x_ref, o_ref):
i = pl.program_id(axis=0) # execution index in the first axis of the grid
o_ref[i] = jnp.exp(x_ref[i])
pallas.num_programs 也接收一个轴,并返回该轴的网格大小。
请注意,虽然 program_id 和 num_programs 是 Triton 特有的术语,但它们很容易被推广以在 TPU 上也有意义。
在 Pallas 中使用 JAX 原语的子集#
因为我们编写的是内核,而不是高阶 HLO 程序,所以一些 JAX 原语可能无法在我们的底层基质中高效表示。但是,我们知道我们可以支持大多数逐元素操作、简单的点积和 JAX 控制流。
虽然我们尚未精确地映射出所有可以在 Pallas 内核中支持的 JAX 原语,但我们当然可以识别出一些不容易降级或不太有用的原语。
conv_general- 卷积通常不会作为底层硬件中的原语提供。gather/scatter- 底层编译器可能不支持非连续的内存读取和写入。
使用 pallas_call 执行 Pallas 内核#
现在我们已经编写了 Pallas 内核(也称为带有 Ref 和额外的 Pallas 原语的 JAX),我们如何在 GPU 或 TPU 上执行它们?我们使用 pallas_call,这是一个高阶函数(类似于 jax.jit 和 jax.pmap),用于执行内核。
pallas_call 的签名如下所示
def pallas_call(
kernel: Callable,
out_shape: Sequence[jax.ShapeDtypeStruct],
*,
in_specs: Sequence[Spec],
out_specs: Sequence[Spec],
grid: Optional[Tuple[int, ...]] = None) -> Callable:
...
当我们向 pallas_call 提供内核时,我们会提供额外的信息。第一个是 out_shape,它告诉内核输出是什么样子(pallas_call 将传递一个与这些对应的 Ref 到内核中进行写入)。其余信息(in_specs、out_specs 和 grid)是关于如何在加速器上调度内核的信息。
pallas_call 的(粗略)语义如下
def pallas_call(kernel, out_shape, *, in_specs, out_specs, grid):
def execute(*args):
outputs = map(empty_ref, out_shape)
grid_indices = map(range, grid)
for indices in itertools.product(*grid_indices): # Could run in parallel!
local_inputs = [in_spec.transform(arg, indices) for arg, in_spec in
zip(args, in_specs)]
local_outputs = [out_spec.transform(arg, indices) for arg, out_spec in
zip(outputs, out_specs)]
kernel(*local_inputs, *local_outputs) # writes to outputs
return execute
具体来说,pallas_call 将在网格迭代空间上“循环”,通过 in_specs 和 out_specs 指定的转换应用于输入和输出。在每次迭代中,内核将在转换后的输入和输出上调用。请注意,迭代空间上的“循环”可以并行执行(例如,在 GPU 上)。pallas_call 也不保证迭代空间上循环迭代的顺序,只是迭代空间的每个成员都会被循环到。像 Triton 和 Mosaic 这样的编译器将具有与网格相关的更具体的操作语义。
转换函数#
pallas_call 的 in_specs 和 out_specs 参数允许以某种方式转换输入和输出。Pallas 现在提供的两个选项是恒等变换(其中输入和输出保持不变)和 BlockSpec,它获取由循环索引确定的 Ref 的固定大小的切片。
BlockSpec 采用 index_map 函数和 block_shape。从逻辑上讲,它将数组沿每个轴切片成 block_shape 大小的块。index_map 函数采用循环索引(来自网格索引集)并将它们映射到块索引。转换函数将 Ref 转换为相应块上 Ref 的逻辑视图。当我们在 block_shape 中的条目中指定 None 时,它对应于在该维度上“映射”,将其从内核中的块中移除。
class BlockSpec:
index_map: Callable[[Tuple[Int, ...]], Tuple[Int, ...]]
block_shape: Tuple[Optional[int], ...]
def transform(self, ref, *loop_indices):
block_indices = self.transform_function(loop_indices)
# Returns a view of `ref` starting at `block_indices` of shape self.block_shape
...
我们还可以想象其他与 pallas_call 一起使用的 Spec,例如,一个与重叠窗口对应的 Spec,用于实现卷积。
Pallas 作为前端的直接好处#
通过为内核编写提供 JAX 前端,我们可以立即获得一些好处。
更灵活的前端#
首先,JAX 用户已经习惯了使用 JAX 及其基于跟踪的转换进行编程的好处(和局限性)。这意味着用户在编写 Pallas 内核时可以使用闭包和其他熟悉的 Python 构造。这与现有的基于 AST 解析的 Triton 前端或 Mosaic 的 MLIR 构建器不同。例如,这使得 Pallas 比 Triton 更适合模板化。
请参阅此示例,了解我们如何在 Python 中使用高阶函数来模板化内核。
def make_kernel(eltwise_kernel):
def add(x_ref, y_ref, o_ref):
x = pl.load(x_ref, ())
y = pl.load(y_ref, ())
pl.store(o_ref, (), eltwise_kernel(x + y))
return add
kernel1 = make_kernel(lambda x: x * 2)
kernel2 = make_kernel(jnp.exp)
pl.pallas_call(kernel1, out_shape=x, grid=1)(1., 1.)
pl.pallas_call(kernel2, out_shape=x, grid=1)(1., 1.)
模拟模式#
通过将内核表示为带有 JAX 原语和一些新的 Pallas 原语的程序,我们还可以将 Pallas 程序直接降级为 StableHLO,并使用 XLA 编译/执行它们。具体来说,pallas_call 可以实现为网格上的 lax.scan。这使我们能够在任何 XLA 支持的平台(甚至是 CPU!)上开发 GPU 或 TPU 内核,并使用 JAX/XLA 调试工具(如 jax.debug.print)调试它们。我们还可以使用更可靠且经过更好测试的 XLA 数值来验证 Triton 和 Mosaic 编译器的正确性。人们还可以想象扰乱 scan 排序,以模拟 GPU 上发生的并行读取和写入。
GPU 示例#
请注意,以下所有示例仅适用于 GPU。它们需要调整块大小才能在 TPU 上工作。
add#
我们修改 add_kernel 示例以使用 BlockSpec 在 (2,) 大小的块上进行操作。
def add_kernel(x_ref, y_ref, o_ref):
# In this code, `x_ref`, `y_ref` and `o_ref` are (2,)-shaped `Ref`s
x = x_ref[:]
y = y_ref[:]
o_ref[:] = x + y
x, y = jnp.arange(8), jnp.arange(8, 16)
add = pl.pallas_call(
add_kernel,
out_shape=jax.ShapeDtypeStruct((8,), jnp.int32),
in_specs=[
pl.BlockSpec((2,), lambda i: i),
pl.BlockSpec((2,), lambda i: i)
],
out_specs=pl.BlockSpec((2,), lambda i: i),
grid=(4,))
add(x, y)
模板化的矩阵乘法#
在此示例中,我们通过对输入数组的行和列块进行展开累加来计算输出的块。我们使用高阶函数将激活函数内联到内核的主体中,以便我们可以发出融合的内核。
def matmul_kernel(x_ref, y_ref, o_ref, *, activation, block_k):
acc = jnp.zeros((x_ref.shape[0], y_ref.shape[1]), jnp.float32)
for k in range(x_ref.shape[1] // block_k):
x = x_ref[:, k*block_k:(k+1)*block_k]
y = y_ref[k*block_k:(k+1)*block_k, :]
acc += x @ y
o_ref[:, :] = activation(acc).astype(o_ref.dtype)
x, y = jnp.ones((512, 256)), jnp.ones((256, 1024))
block_shape = 128, 256, 128
@partial(jax.jit, static_argnames=["block_shape", "activation"])
def matmul(x, y, *, block_shape, activation):
block_m, block_n, block_k = block_shape
fused_matmul = pl.pallas_call(
partial(matmul_kernel, block_k=block_k, activation=activation),
out_shape=jax.ShapeDtypeStruct((x.shape[0], y.shape[1],), jnp.float32),
in_specs=[
pl.BlockSpec((block_m, x.shape[1]), lambda i, j: (i, 0)),
pl.BlockSpec((y.shape[0], block_n), lambda i, j: (0, j))
],
out_specs=pl.BlockSpec((block_m, block_n), lambda i, j: (i, j)),
grid=(4, 4),
)
return fused_matmul(x, y)
z = matmul(x, y, block_shape=block_shape, activation=jax.nn.gelu)
降低 Pallas#
在用户表达他们的 Pallas 内核后,我们会根据目标后端将它们降低为不同的表示形式。在 GPU 上,我们将 Pallas 降低为 Triton IR,而在 TPU 上,我们将 Pallas 降低为 Mosaic。
将 Pallas 降低为 GPU 的 Triton#
将 Pallas 降低为 Triton 很简单,因为 Pallas 在设计时就考虑了 Triton 作为目标语言。Pallas 和 Triton 之间的主要区别在于 Triton 没有 BlockSpec 的概念,并且在执行内存加载和存储时使用指针而不是索引。
Triton 支持指针作为其语言中的数组元素类型,在 Triton 中,您可以从指针数组加载并存储到指针数组。在 Pallas 中,当给定一个形状为 (4, 5) 的 Ref,x_ref,然后执行类似于 x_ref[3, 2] 的操作时,我们需要将其降低为计算 x_ref 中适当的行优先位置的 Triton 指针(即,执行 5 * 3 + 2 * 1)。类似地,当我们降低到 Triton 的切片时,例如 x_ref[4, :],我们需要生成一个指针数组 5 * 4 + jnp.arange(3)。
除此之外,降低到 Triton 非常简单。JAX 点积可以降低为 Triton 点积,JAX 一元原语可以降低为它们的 Triton 等价物。Triton 的原子操作通过新的 Pallas 原子原语降低。
将 Pallas 降低到 TPU 的 Mosaic#
Mosaic 消耗(大多数)标准方言 MLIR 并发出 LLO 以编译为 TPU。可以通过将 JAX 原语转换为 MLIR(主要是 vector 和 arith 方言)将 Pallas 降低为 Mosaic。BlockSpec 可以转换为管道计划(即 Mosaic 中的 transform_func)。
转换 Pallas#
一个自然的问题是,JAX 转换如何与 Pallas 内核交互?有两种主要方式:Pallas 内核内的转换和 Pallas 内核外的转换。
Pallas 内核内的转换实际上应该“正常工作”,只要我们能够降低转换后的代码即可。例如,我们可以在 JAX 内核内部使用 jax.grad(jnp.sin)(...),因为我们可以将 cos 降低到 Triton 和 Mosaic。但是,我们可能无法降低 jax.vmap(lax.dynamic_slice),因为它可能会变成我们无法降低的 gather。
从外部 JAX 程序转换 Pallas 内核可能是更有趣的情况。我们如何处理诸如 vmap(pallas_call) 和 grad(pallas_call) 之类的事情?
vmap-of-pallas_call#
vmap 自动向量化 JAX 程序。虽然内核编写者可能希望精确控制批处理内核与未批处理变体的行为差异,但我们可以为 pallas_call 提供合理的默认 vmap 规则,同时提供 jax.custom_vmap 自定义机制。当 pallas_call 被 vmap 处理时,我们会增强 pallas_call 以使其具有与新批处理维度相对应的额外网格维度,并转换 BlockSpec 以处理沿该维度的索引。
grad-of-pallas_call#
pallas_call 的 grad 启用内核的自动微分。 jax.grad 分解为三个不同变换的应用:jvp、partial_eval 和 transpose。原则上,在为 pallas_call 实现这些规则时,我们可以重用 JAX 的大部分基础设施(因为它与现有的 JAX 高阶原语的行为非常相似)。
然而,由于内存访问的转置方式,内核的自动微分可能会导致性能下降。如果我们编写一个具有重叠并行读取和不相交并行写入的 GPU 内核,我们会自动将其转置为一个具有重叠并行写入(原子操作时速度很慢)和不相交并行读取的内核。为了发出一个能更好利用共享内存并行性的内核,我们需要重新排序循环并更改内核的向量化方式。不幸的是,我们在 Pallas 中没有适合这种操作的程序表示。自动高效微分内核的一个潜在方向是探索不同的表示形式,例如 Dex 中的表示形式。我们也可以研究 Enzyme 如何处理这个问题。然而,Pallas 内核的 AD 对于一类能有效进行转置的内核(例如,逐元素内核)仍然可能有用。
但总的来说,jax.custom_vjp 是一个可行的退出策略,用于表达与 jax.grad 一起工作的 Pallas 内核。
其他变换#
我们可以想象其他 JAX 变换应用于我们尚未明确探索的 Pallas 内核。例如,checkify 是一个执行函数式错误处理的 JAX 变换。我们可以想象将 checkify 与 pallas_call 一起使用,以允许从 GPU 内核中输出错误代码,这些代码指示是否产生了 OOB 访问或 NaN。
另一个要集成的潜在变换是 custom_partitioning,以便使自动可分区的内核能够与 pjit 一起使用。