自定义导数规则#
![]()

在 JAX 中定义微分规则有两种方法
使用
jax.custom_jvp和jax.custom_vjp为已经可以进行 JAX 转换的 Python 函数定义自定义微分规则;以及定义新的
core.Primitive实例及其所有转换规则,例如调用来自其他系统(如求解器、模拟器或通用数值计算系统)的函数。
此笔记本是关于 #1 的。要阅读关于 #2 的内容,请参阅关于添加原语的笔记本。
有关 JAX 自动微分 API 的介绍,请参阅自动微分手册。此笔记本假定您对 jax.jvp 和 jax.grad 以及 JVP 和 VJP 的数学含义有一定了解。
总结#
使用 jax.custom_jvp 自定义 JVP#
import jax.numpy as jnp
from jax import custom_jvp
@custom_jvp
def f(x, y):
return jnp.sin(x) * y
@f.defjvp
def f_jvp(primals, tangents):
x, y = primals
x_dot, y_dot = tangents
primal_out = f(x, y)
tangent_out = jnp.cos(x) * x_dot * y + jnp.sin(x) * y_dot
return primal_out, tangent_out
from jax import jvp, grad
print(f(2., 3.))
y, y_dot = jvp(f, (2., 3.), (1., 0.))
print(y)
print(y_dot)
print(grad(f)(2., 3.))
2.7278922
2.7278922
-1.2484405
-1.2484405
# Equivalent alternative using the defjvps convenience wrapper
@custom_jvp
def f(x, y):
return jnp.sin(x) * y
f.defjvps(lambda x_dot, primal_out, x, y: jnp.cos(x) * x_dot * y,
lambda y_dot, primal_out, x, y: jnp.sin(x) * y_dot)
print(f(2., 3.))
y, y_dot = jvp(f, (2., 3.), (1., 0.))
print(y)
print(y_dot)
print(grad(f)(2., 3.))
2.7278922
2.7278922
-1.2484405
-1.2484405
使用 jax.custom_vjp 自定义 VJP#
from jax import custom_vjp
@custom_vjp
def f(x, y):
return jnp.sin(x) * y
def f_fwd(x, y):
# Returns primal output and residuals to be used in backward pass by f_bwd.
return f(x, y), (jnp.cos(x), jnp.sin(x), y)
def f_bwd(res, g):
cos_x, sin_x, y = res # Gets residuals computed in f_fwd
return (cos_x * g * y, sin_x * g)
f.defvjp(f_fwd, f_bwd)
print(grad(f)(2., 3.))
-1.2484405
示例问题#
为了了解 jax.custom_jvp 和 jax.custom_vjp 旨在解决哪些问题,让我们看几个例子。下一节将更详细地介绍 jax.custom_jvp 和 jax.custom_vjp API。
数值稳定性#
jax.custom_jvp 的一个应用是提高微分的数值稳定性。
假设我们想要编写一个名为 log1pexp 的函数,该函数计算 \(x \mapsto \log ( 1 + e^x )\)。我们可以使用 jax.numpy 编写它
def log1pexp(x):
return jnp.log(1. + jnp.exp(x))
log1pexp(3.)
Array(3.0485873, dtype=float32, weak_type=True)
由于它是用 jax.numpy 编写的,因此可以进行 JAX 转换
from jax import jit, grad, vmap
print(jit(log1pexp)(3.))
print(jit(grad(log1pexp))(3.))
print(vmap(jit(grad(log1pexp)))(jnp.arange(3.)))
3.0485873
0.95257413
[0.5 0.7310586 0.8807971]
但是这里潜伏着一个数值稳定性问题
print(grad(log1pexp)(100.))
nan
这看起来不对!毕竟,\(x \mapsto \log (1 + e^x)\) 的导数是 \(x \mapsto \frac{e^x}{1 + e^x}\),因此对于较大的 \(x\) 值,我们期望该值约为 1。
我们可以通过查看梯度计算的 jaxpr 来更深入地了解正在发生的事情
from jax import make_jaxpr
make_jaxpr(grad(log1pexp))(100.)
{ lambda ; a:f32[]. let
b:f32[] = exp a
c:f32[] = add 1.0 b
_:f32[] = log c
d:f32[] = div 1.0 c
e:f32[] = mul d b
in (e,) }
逐步执行 jaxpr 的求值过程,我们可以看到最后一行将涉及乘以浮点数学将舍入为 0 和 \(\infty\) 的值,这不是一个好主意。也就是说,我们实际上是在为较大的 x 求值 lambda x: (1 / (1 + jnp.exp(x))) * jnp.exp(x),这实际上变成了 0. * jnp.inf。
与其生成如此大和小的数值,寄希望于浮点数并不总是能提供的抵消,不如将导数函数表达为更数值稳定的程序。特别是,我们可以编写一个更接近于求值数学表达式 \(1 - \frac{1}{1 + e^x}\) 的程序,没有任何抵消的迹象。
这个问题很有趣,因为即使我们对 log1pexp 的定义已经可以进行 JAX 微分(并使用 jit、vmap 等进行转换),我们对将标准自动微分规则应用于构成 log1pexp 的原语并组成结果并不满意。相反,我们希望指定如何将整个函数 log1pexp 作为整体进行微分,从而更好地排列这些指数。
这是自定义导数规则应用于已经可以进行 JAX 转换的 Python 函数的一个应用:指定如何对复合函数进行微分,同时仍然使用其原始 Python 定义进行其他转换(如 jit、vmap 等)。
这是使用 jax.custom_jvp 的解决方案
from jax import custom_jvp
@custom_jvp
def log1pexp(x):
return jnp.log(1. + jnp.exp(x))
@log1pexp.defjvp
def log1pexp_jvp(primals, tangents):
x, = primals
x_dot, = tangents
ans = log1pexp(x)
ans_dot = (1 - 1/(1 + jnp.exp(x))) * x_dot
return ans, ans_dot
print(grad(log1pexp)(100.))
1.0
print(jit(log1pexp)(3.))
print(jit(grad(log1pexp))(3.))
print(vmap(jit(grad(log1pexp)))(jnp.arange(3.)))
3.0485873
0.95257413
[0.5 0.7310586 0.8807971]
这是一个 defjvps 便利包装器,用于表达相同的内容
@custom_jvp
def log1pexp(x):
return jnp.log(1. + jnp.exp(x))
log1pexp.defjvps(lambda t, ans, x: (1 - 1/(1 + jnp.exp(x))) * t)
print(grad(log1pexp)(100.))
print(jit(log1pexp)(3.))
print(jit(grad(log1pexp))(3.))
print(vmap(jit(grad(log1pexp)))(jnp.arange(3.)))
1.0
3.0485873
0.95257413
[0.5 0.7310586 0.8807971]
强制执行微分约定#
一个相关的应用是强制执行微分约定,可能是在边界上。
考虑函数 \(f : \mathbb{R}_+ \to \mathbb{R}_+\),其中 \(f(x) = \frac{x}{1 + \sqrt{x}}\),我们取 \(\mathbb{R}_+ = [0, \infty)\)。我们可以像这样实现 \(f\) 的程序
def f(x):
return x / (1 + jnp.sqrt(x))
作为 \(\mathbb{R}\)(完整的实数线)上的数学函数,\(f\) 在零处不可微(因为定义导数的极限从左侧不存在)。相应地,自动微分产生一个 nan 值
print(grad(f)(0.))
nan
但是,如果我们从数学上将 \(f\) 视为 \(\mathbb{R}_+\) 上的函数,那么它在 0 处是可微的 [Rudin 的《数学分析原理》定义 5.1,或 Tao 的《分析 I》第 3 版定义 10.1.1 和示例 10.1.6]。或者,我们可能会说,按照约定,我们希望考虑从右侧的定向导数。因此,Python 函数 grad(f) 在 0.0 处返回一个合理的值,即 1.0。默认情况下,JAX 的微分机制假定所有函数都是在 \(\mathbb{R}\) 上定义的,因此此处不会产生 1.0。
我们可以使用自定义 JVP 规则!特别是,我们可以根据 \(\mathbb{R}_+\) 上的导数函数 \(x \mapsto \frac{\sqrt{x} + 2}{2(\sqrt{x} + 1)^2}\) 定义 JVP 规则。
@custom_jvp
def f(x):
return x / (1 + jnp.sqrt(x))
@f.defjvp
def f_jvp(primals, tangents):
x, = primals
x_dot, = tangents
ans = f(x)
ans_dot = ((jnp.sqrt(x) + 2) / (2 * (jnp.sqrt(x) + 1)**2)) * x_dot
return ans, ans_dot
print(grad(f)(0.))
1.0
这是便利包装器版本
@custom_jvp
def f(x):
return x / (1 + jnp.sqrt(x))
f.defjvps(lambda t, ans, x: ((jnp.sqrt(x) + 2) / (2 * (jnp.sqrt(x) + 1)**2)) * t)
print(grad(f)(0.))
1.0
梯度裁剪#
虽然在某些情况下我们想要表达数学微分计算,但在其他情况下,我们甚至可能想要偏离数学来调整自动微分执行的计算。一个典型的例子是反向模式梯度裁剪。
对于梯度裁剪,我们可以使用 jnp.clip 以及 jax.custom_vjp 仅反向模式规则
from functools import partial
from jax import custom_vjp
@custom_vjp
def clip_gradient(lo, hi, x):
return x # identity function
def clip_gradient_fwd(lo, hi, x):
return x, (lo, hi) # save bounds as residuals
def clip_gradient_bwd(res, g):
lo, hi = res
return (None, None, jnp.clip(g, lo, hi)) # use None to indicate zero cotangents for lo and hi
clip_gradient.defvjp(clip_gradient_fwd, clip_gradient_bwd)
import matplotlib.pyplot as plt
from jax import vmap
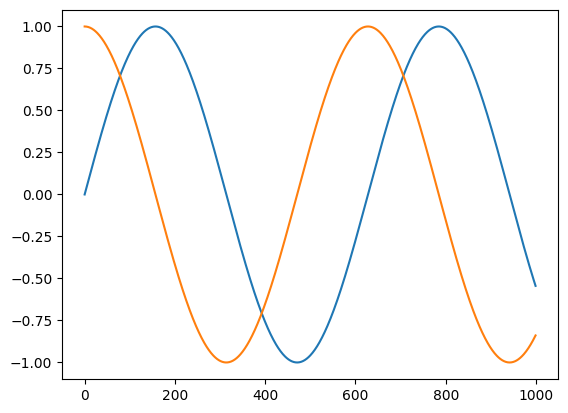
t = jnp.linspace(0, 10, 1000)
plt.plot(jnp.sin(t))
plt.plot(vmap(grad(jnp.sin))(t))
[<matplotlib.lines.Line2D at 0x7ff5e5865030>]
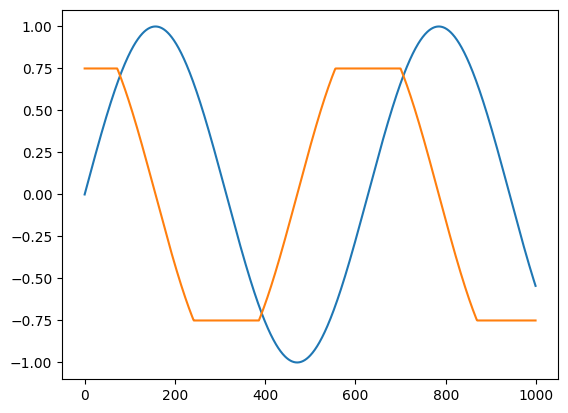
def clip_sin(x):
x = clip_gradient(-0.75, 0.75, x)
return jnp.sin(x)
plt.plot(clip_sin(t))
plt.plot(vmap(grad(clip_sin))(t))
[<matplotlib.lines.Line2D at 0x7ff5e56db310>]
Python 调试#
另一个受开发工作流程而非数值驱动的应用是在反向模式自动微分的反向传递中设置 pdb 调试器跟踪。
在尝试找出 nan 运行时错误的根源,或者只是仔细检查正在传播的余切(梯度)值时,在反向传递中插入与原始计算中的特定点对应的调试器可能很有用。您可以使用 jax.custom_vjp 执行此操作。
我们将示例推迟到下一节。
迭代实现的隐式函数微分#
这个例子在数学上非常深入!
jax.custom_vjp 的另一个应用是对可以进行 JAX 转换(通过 jit、vmap 等)但出于某种原因不能高效地进行 JAX 微分的函数进行反向模式微分,这可能是因为它们涉及 lax.while_loop。(不可能产生一个 XLA HLO 程序来高效地计算 XLA HLO While 循环的反向模式导数,因为这将需要一个具有无限内存使用的程序,这在 XLA HLO 中无法表达,至少不能通过 infeed/outfeed 的副作用交互。)
例如,考虑这个 fixed_point 例程,它通过在 while_loop 中迭代应用函数来计算不动点
from jax.lax import while_loop
def fixed_point(f, a, x_guess):
def cond_fun(carry):
x_prev, x = carry
return jnp.abs(x_prev - x) > 1e-6
def body_fun(carry):
_, x = carry
return x, f(a, x)
_, x_star = while_loop(cond_fun, body_fun, (x_guess, f(a, x_guess)))
return x_star
这是用于数值求解方程 \(x = f(a, x)\) 的迭代过程,通过迭代 \(x_{t+1} = f(a, x_t)\),直到 \(x_{t+1}\) 足够接近 \(x_t\)。结果 \(x^*\) 取决于参数 \(a\),因此我们可以认为存在一个由方程 \(x = f(a, x)\) 隐式定义的函数 \(a \mapsto x^*(a)\)。
我们可以使用 fixed_point 来运行迭代过程以达到收敛,例如运行牛顿法来计算平方根,同时仅执行加法、乘法和除法
def newton_sqrt(a):
update = lambda a, x: 0.5 * (x + a / x)
return fixed_point(update, a, a)
print(newton_sqrt(2.))
1.4142135
我们也可以对函数进行 vmap 或 jit
print(jit(vmap(newton_sqrt))(jnp.array([1., 2., 3., 4.])))
[1. 1.4142135 1.7320509 2. ]
由于 while_loop 的存在,我们无法应用反向模式自动微分。但实际上,我们也不想这样做:与其对 fixed_point 的实现及其所有迭代进行微分,不如利用其数学结构来做一些在内存效率上更高(并且在本例中,在 FLOP 效率上也更高!)的事情。我们可以使用隐函数定理 [Bertsekas 的《非线性规划》第二版,命题 A.25],它保证了(在某些条件下)我们即将使用的数学对象的存在。本质上,我们在解处进行线性化,并迭代地求解这些线性方程以计算我们想要的导数。
再次考虑方程 \(x = f(a, x)\) 和函数 \(x^*\)。我们想要评估像 \(v^\mathsf{T} \mapsto v^\mathsf{T} \partial x^*(a_0)\) 这样的向量-雅可比矩阵积。
至少在我们要微分的点 \(a_0\) 周围的一个开邻域内,假设对于所有 \(a\),方程 \(x^*(a) = f(a, x^*(a))\) 都成立。由于两边作为 \(a\) 的函数相等,它们的导数也必须相等,因此我们对两边进行微分
\(\qquad \partial x^*(a) = \partial_0 f(a, x^*(a)) + \partial_1 f(a, x^*(a)) \partial x^*(a)\).
令 \(A = \partial_1 f(a_0, x^*(a_0))\) 和 \(B = \partial_0 f(a_0, x^*(a_0))\),我们可以更简单地将我们想要的量写为
\(\qquad \partial x^*(a_0) = B + A \partial x^*(a_0)\),
或者,通过重新排列,
\(\qquad \partial x^*(a_0) = (I - A)^{-1} B\).
这意味着我们可以评估像这样的向量-雅可比矩阵积
\(\qquad v^\mathsf{T} \partial x^*(a_0) = v^\mathsf{T} (I - A)^{-1} B = w^\mathsf{T} B\),
其中 \(w^\mathsf{T} = v^\mathsf{T} (I - A)^{-1}\),或者等价地,\(w^\mathsf{T} = v^\mathsf{T} + w^\mathsf{T} A\),或者等价地,\(w^\mathsf{T}\) 是映射 \(u^\mathsf{T} \mapsto v^\mathsf{T} + u^\mathsf{T} A\) 的不动点。最后一种描述方式为我们提供了一种用对 fixed_point 的调用来编写 fixed_point 的 VJP 的方法!此外,在展开 \(A\) 和 \(B\) 后,我们可以看到我们只需要评估 \(f\) 在 \((a_0, x^*(a_0))\) 处的 VJP。
这是重点
from jax import vjp
@partial(custom_vjp, nondiff_argnums=(0,))
def fixed_point(f, a, x_guess):
def cond_fun(carry):
x_prev, x = carry
return jnp.abs(x_prev - x) > 1e-6
def body_fun(carry):
_, x = carry
return x, f(a, x)
_, x_star = while_loop(cond_fun, body_fun, (x_guess, f(a, x_guess)))
return x_star
def fixed_point_fwd(f, a, x_init):
x_star = fixed_point(f, a, x_init)
return x_star, (a, x_star)
def fixed_point_rev(f, res, x_star_bar):
a, x_star = res
_, vjp_a = vjp(lambda a: f(a, x_star), a)
a_bar, = vjp_a(fixed_point(partial(rev_iter, f),
(a, x_star, x_star_bar),
x_star_bar))
return a_bar, jnp.zeros_like(x_star)
def rev_iter(f, packed, u):
a, x_star, x_star_bar = packed
_, vjp_x = vjp(lambda x: f(a, x), x_star)
return x_star_bar + vjp_x(u)[0]
fixed_point.defvjp(fixed_point_fwd, fixed_point_rev)
print(newton_sqrt(2.))
1.4142135
print(grad(newton_sqrt)(2.))
print(grad(grad(newton_sqrt))(2.))
0.35355338
-0.088388346
我们可以通过微分 jnp.sqrt 来检查我们的答案,它使用完全不同的实现
print(grad(jnp.sqrt)(2.))
print(grad(grad(jnp.sqrt))(2.))
0.35355338
-0.08838835
这种方法的一个限制是,参数 f 不能闭包任何涉及微分的值。也就是说,您可能会注意到我们在 fixed_point 的参数列表中明确地保留了参数 a。对于此用例,请考虑使用底层原语 lax.custom_root,它允许在具有自定义求根函数的闭包变量中进行微分。
jax.custom_jvp 和 jax.custom_vjp API 的基本用法#
使用 jax.custom_jvp 定义前向模式(以及间接的,反向模式)规则#
这里有一个使用 jax.custom_jvp 的规范基本示例,其中注释使用类似 Haskell 的类型签名
from jax import custom_jvp
import jax.numpy as jnp
# f :: a -> b
@custom_jvp
def f(x):
return jnp.sin(x)
# f_jvp :: (a, T a) -> (b, T b)
def f_jvp(primals, tangents):
x, = primals
t, = tangents
return f(x), jnp.cos(x) * t
f.defjvp(f_jvp)
<function __main__.f_jvp(primals, tangents)>
from jax import jvp
print(f(3.))
y, y_dot = jvp(f, (3.,), (1.,))
print(y)
print(y_dot)
0.14112
0.14112
-0.9899925
换句话说,我们从一个原始函数 f 开始,它接受类型为 a 的输入并产生类型为 b 的输出。我们将其与 JVP 规则函数 f_jvp 相关联,该函数接受一对表示类型为 a 的原始输入和类型为 T a 的相应切线输入的输入,并产生一对表示类型为 b 的原始输出和类型为 T b 的切线输出的输出。切线输出应该是切线输入的线性函数。
您也可以使用 f.defjvp 作为装饰器,如
@custom_jvp
def f(x):
...
@f.defjvp
def f_jvp(primals, tangents):
...
即使我们只定义了一个 JVP 规则,而没有定义 VJP 规则,我们也可以对 f 使用前向和反向模式微分。JAX 将自动转置来自我们的自定义 JVP 规则的切线值的线性计算,其计算 VJP 的效率就好像我们手动编写规则一样
from jax import grad
print(grad(f)(3.))
print(grad(grad(f))(3.))
-0.9899925
-0.14112
为了使自动转置工作,JVP 规则的输出切线必须是输入切线的线性函数。否则会引发转置错误。
多个参数的工作方式如下
@custom_jvp
def f(x, y):
return x ** 2 * y
@f.defjvp
def f_jvp(primals, tangents):
x, y = primals
x_dot, y_dot = tangents
primal_out = f(x, y)
tangent_out = 2 * x * y * x_dot + x ** 2 * y_dot
return primal_out, tangent_out
print(grad(f)(2., 3.))
12.0
defjvps 便捷包装器使我们可以为每个参数单独定义一个 JVP,结果将分别计算然后求和
@custom_jvp
def f(x):
return jnp.sin(x)
f.defjvps(lambda t, ans, x: jnp.cos(x) * t)
print(grad(f)(3.))
-0.9899925
这里有一个使用多个参数的 defjvps 示例
@custom_jvp
def f(x, y):
return x ** 2 * y
f.defjvps(lambda x_dot, primal_out, x, y: 2 * x * y * x_dot,
lambda y_dot, primal_out, x, y: x ** 2 * y_dot)
print(grad(f)(2., 3.))
print(grad(f, 0)(2., 3.)) # same as above
print(grad(f, 1)(2., 3.))
12.0
12.0
4.0
作为一种简写方式,使用 defjvps,您可以传递一个 None 值来指示特定参数的 JVP 为零
@custom_jvp
def f(x, y):
return x ** 2 * y
f.defjvps(lambda x_dot, primal_out, x, y: 2 * x * y * x_dot,
None)
print(grad(f)(2., 3.))
print(grad(f, 0)(2., 3.)) # same as above
print(grad(f, 1)(2., 3.))
12.0
12.0
0.0
使用关键字参数调用 jax.custom_jvp 函数,或者编写带有默认参数的 jax.custom_jvp 函数定义都是允许的,只要它们可以基于标准库 inspect.signature 机制检索的函数签名明确地映射到位置参数即可。
当您不执行微分时,会调用函数 f,就像它没有被 jax.custom_jvp 修饰一样
@custom_jvp
def f(x):
print('called f!') # a harmless side-effect
return jnp.sin(x)
@f.defjvp
def f_jvp(primals, tangents):
print('called f_jvp!') # a harmless side-effect
x, = primals
t, = tangents
return f(x), jnp.cos(x) * t
from jax import vmap, jit
print(f(3.))
called f!
0.14112
print(vmap(f)(jnp.arange(3.)))
print(jit(f)(3.))
called f!
[0. 0.84147096 0.9092974 ]
called f!
0.14112
在微分期间会调用自定义 JVP 规则,无论是前向还是反向
y, y_dot = jvp(f, (3.,), (1.,))
print(y_dot)
called f_jvp!
called f!
-0.9899925
print(grad(f)(3.))
called f_jvp!
called f!
-0.9899925
请注意,f_jvp 调用 f 来计算原始输出。在更高阶微分的上下文中,只有当规则调用原始 f 来计算原始输出时,微分变换的每次应用才会使用自定义 JVP 规则。(这表示一种基本的权衡,我们无法在我们的规则中使用 f 的评估的中间值,并且 还要使规则应用于所有阶的高阶微分。)
grad(grad(f))(3.)
called f_jvp!
called f_jvp!
called f!
Array(-0.14112, dtype=float32, weak_type=True)
您可以将 Python 控制流与 jax.custom_jvp 一起使用
@custom_jvp
def f(x):
if x > 0:
return jnp.sin(x)
else:
return jnp.cos(x)
@f.defjvp
def f_jvp(primals, tangents):
x, = primals
x_dot, = tangents
ans = f(x)
if x > 0:
return ans, 2 * x_dot
else:
return ans, 3 * x_dot
print(grad(f)(1.))
print(grad(f)(-1.))
2.0
3.0
使用 jax.custom_vjp 定义仅限自定义反向模式的规则#
虽然 jax.custom_jvp 足以控制前向和(通过 JAX 的自动转置)反向模式微分行为,但在某些情况下,我们可能需要直接控制 VJP 规则,例如在上面提出的后两个示例问题中。我们可以使用 jax.custom_vjp 来做到这一点
from jax import custom_vjp
import jax.numpy as jnp
# f :: a -> b
@custom_vjp
def f(x):
return jnp.sin(x)
# f_fwd :: a -> (b, c)
def f_fwd(x):
return f(x), jnp.cos(x)
# f_bwd :: (c, CT b) -> CT a
def f_bwd(cos_x, y_bar):
return (cos_x * y_bar,)
f.defvjp(f_fwd, f_bwd)
from jax import grad
print(f(3.))
print(grad(f)(3.))
0.14112
-0.9899925
换句话说,我们再次从一个原始函数 f 开始,该函数接受类型为 a 的输入并产生类型为 b 的输出。我们将其与两个函数 f_fwd 和 f_bwd 相关联,这两个函数分别描述了如何执行反向模式自动微分的前向和后向传递。
函数 f_fwd 描述了前向传递,不仅包括原始计算,还包括要保存哪些值以在后向传递中使用。它的输入签名与原始函数 f 的输入签名相同,因为它接受类型为 a 的原始输入。但是,作为输出,它产生一个对,其中第一个元素是原始输出 b,第二个元素是任何类型为 c 的“残差”数据,该数据存储供后向传递使用。(第二个输出类似于 PyTorch 的 save_for_backward 机制。)
函数 f_bwd 描述了反向传递。它接受两个输入,第一个是由 f_fwd 生成的类型为 c 的残差数据,第二个是与原始函数的输出相对应的类型为 CT b 的输出余切。它生成一个类型为 CT a 的输出,表示与原始函数输入相对应的余切。特别是,f_bwd 的输出必须是一个序列(例如,一个元组),其长度等于原始函数的参数数量。
所以多个参数像这样工作
from jax import custom_vjp
@custom_vjp
def f(x, y):
return jnp.sin(x) * y
def f_fwd(x, y):
return f(x, y), (jnp.cos(x), jnp.sin(x), y)
def f_bwd(res, g):
cos_x, sin_x, y = res
return (cos_x * g * y, sin_x * g)
f.defvjp(f_fwd, f_bwd)
print(grad(f)(2., 3.))
-1.2484405
使用关键字参数调用 jax.custom_vjp 函数,或者使用默认参数编写 jax.custom_vjp 函数定义,都是允许的,只要它们可以根据标准库 inspect.signature 机制检索的函数签名明确地映射到位置参数即可。
与 jax.custom_jvp 一样,如果未应用微分,则不会调用由 f_fwd 和 f_bwd 组成的自定义 VJP 规则。如果评估该函数,或使用 jit、vmap 或其他非微分转换进行转换,则只会调用 f。
@custom_vjp
def f(x):
print("called f!")
return jnp.sin(x)
def f_fwd(x):
print("called f_fwd!")
return f(x), jnp.cos(x)
def f_bwd(cos_x, y_bar):
print("called f_bwd!")
return (cos_x * y_bar,)
f.defvjp(f_fwd, f_bwd)
print(f(3.))
called f!
0.14112
print(grad(f)(3.))
called f_fwd!
called f!
called f_bwd!
-0.9899925
y, f_vjp = vjp(f, 3.)
print(y)
called f_fwd!
called f!
0.14112
print(f_vjp(1.))
called f_bwd!
(Array(-0.9899925, dtype=float32, weak_type=True),)
前向模式自动微分不能在 jax.custom_vjp 函数上使用,并且会引发错误
from jax import jvp
try:
jvp(f, (3.,), (1.,))
except TypeError as e:
print('ERROR! {}'.format(e))
called f_fwd!
called f!
ERROR! can't apply forward-mode autodiff (jvp) to a custom_vjp function.
如果想要同时使用前向模式和反向模式,请改用 jax.custom_jvp。
我们可以将 jax.custom_vjp 与 pdb 一起使用,以在反向传递中插入调试器跟踪
import pdb
@custom_vjp
def debug(x):
return x # acts like identity
def debug_fwd(x):
return x, x
def debug_bwd(x, g):
pdb.set_trace()
return g
debug.defvjp(debug_fwd, debug_bwd)
def foo(x):
y = x ** 2
y = debug(y) # insert pdb in corresponding backward pass step
return jnp.sin(y)
jax.grad(foo)(3.)
> <ipython-input-113-b19a2dc1abf7>(12)debug_bwd()
-> return g
(Pdb) p x
Array(9., dtype=float32)
(Pdb) p g
Array(-0.91113025, dtype=float32)
(Pdb) q
更多特性和细节#
使用 list / tuple / dict 容器(和其他 pytrees)#
您应该期望像列表、元组、命名元组和字典这样的标准 Python 容器以及它们的嵌套版本都能正常工作。一般来说,只要它们的结构符合类型约束,任何 pytrees 都是允许的。
这是一个关于 jax.custom_jvp 的人为示例
from collections import namedtuple
Point = namedtuple("Point", ["x", "y"])
@custom_jvp
def f(pt):
x, y = pt.x, pt.y
return {'a': x ** 2,
'b': (jnp.sin(x), jnp.cos(y))}
@f.defjvp
def f_jvp(primals, tangents):
pt, = primals
pt_dot, = tangents
ans = f(pt)
ans_dot = {'a': 2 * pt.x * pt_dot.x,
'b': (jnp.cos(pt.x) * pt_dot.x, -jnp.sin(pt.y) * pt_dot.y)}
return ans, ans_dot
def fun(pt):
dct = f(pt)
return dct['a'] + dct['b'][0]
pt = Point(1., 2.)
print(f(pt))
{'a': 1.0, 'b': (Array(0.84147096, dtype=float32, weak_type=True), Array(-0.41614684, dtype=float32, weak_type=True))}
print(grad(fun)(pt))
Point(x=Array(2.5403023, dtype=float32, weak_type=True), y=Array(0., dtype=float32, weak_type=True))
这是一个关于 jax.custom_vjp 的类似人为示例
@custom_vjp
def f(pt):
x, y = pt.x, pt.y
return {'a': x ** 2,
'b': (jnp.sin(x), jnp.cos(y))}
def f_fwd(pt):
return f(pt), pt
def f_bwd(pt, g):
a_bar, (b0_bar, b1_bar) = g['a'], g['b']
x_bar = 2 * pt.x * a_bar + jnp.cos(pt.x) * b0_bar
y_bar = -jnp.sin(pt.y) * b1_bar
return (Point(x_bar, y_bar),)
f.defvjp(f_fwd, f_bwd)
def fun(pt):
dct = f(pt)
return dct['a'] + dct['b'][0]
pt = Point(1., 2.)
print(f(pt))
{'a': 1.0, 'b': (Array(0.84147096, dtype=float32, weak_type=True), Array(-0.41614684, dtype=float32, weak_type=True))}
print(grad(fun)(pt))
Point(x=Array(2.5403023, dtype=float32, weak_type=True), y=Array(-0., dtype=float32, weak_type=True))
处理不可微分的参数#
某些用例,如最后一个示例问题,需要将不可微分的参数(如函数值参数)传递给具有自定义微分规则的函数,并将这些参数也传递给规则本身。在 fixed_point 的情况下,函数参数 f 就是这样一个不可微分的参数。jax.experimental.odeint 也会出现类似的情况。
jax.custom_jvp 与 nondiff_argnums#
使用 jax.custom_jvp 的可选参数 nondiff_argnums 来指示这些参数。这是一个关于 jax.custom_jvp 的示例
from functools import partial
@partial(custom_jvp, nondiff_argnums=(0,))
def app(f, x):
return f(x)
@app.defjvp
def app_jvp(f, primals, tangents):
x, = primals
x_dot, = tangents
return f(x), 2. * x_dot
print(app(lambda x: x ** 3, 3.))
27.0
print(grad(app, 1)(lambda x: x ** 3, 3.))
2.0
请注意这里的陷阱:无论这些参数出现在参数列表中的什么位置,它们都会被放置在相应 JVP 规则的签名的开头。这是另一个示例
@partial(custom_jvp, nondiff_argnums=(0, 2))
def app2(f, x, g):
return f(g((x)))
@app2.defjvp
def app2_jvp(f, g, primals, tangents):
x, = primals
x_dot, = tangents
return f(g(x)), 3. * x_dot
print(app2(lambda x: x ** 3, 3., lambda y: 5 * y))
3375.0
print(grad(app2, 1)(lambda x: x ** 3, 3., lambda y: 5 * y))
3.0
jax.custom_vjp 与 nondiff_argnums#
jax.custom_vjp 也存在类似的选项,同样,约定是将不可微分的参数作为 _bwd 规则的第一个参数传递,无论它们在原始函数的签名中出现在什么位置。_fwd 规则的签名保持不变 - 它与原始函数的签名相同。这是一个示例
@partial(custom_vjp, nondiff_argnums=(0,))
def app(f, x):
return f(x)
def app_fwd(f, x):
return f(x), x
def app_bwd(f, x, g):
return (5 * g,)
app.defvjp(app_fwd, app_bwd)
print(app(lambda x: x ** 2, 4.))
16.0
print(grad(app, 1)(lambda x: x ** 2, 4.))
5.0
有关其他用法示例,请参阅上面的 fixed_point。
对于数组值参数,您不需要使用 nondiff_argnums,例如具有整数 dtype 的参数。相反,nondiff_argnums 应该仅用于不对应于 JAX 类型(本质上不对应于数组类型)的参数值,例如 Python 可调用对象或字符串。如果 JAX 检测到 nondiff_argnums 指示的参数包含 JAX Tracer,则会引发错误。上面的 clip_gradient 函数就是一个很好的例子,说明如何不为整数 dtype 数组参数使用 nondiff_argnums。